分布式ID生成器
分布式ID生成器,是分布式系统中最基础的一部分。通过学习分布式ID生成器设计,可以把握分布式系统设计的核心关键。
引子:为什么需要分布式ID生成器?
- 大规模数据要求数据分区分库,需要保证业务主键不冲突
- 多实例微服务,需要保证产生消息主键不冲突
- 用户行为事件,如何保证顺序
- …
一 常见方案
1.1 基于UUID
提到分布式ID,最容易想到的是UUID。UUID可以保证不冲突,但不保证顺序,一般不建议使用。
优点
- 实现简单
- 无外部依赖,可本地生成
缺点
- 无序,写入性能差
- 基于MAC地址生成UUID的算法可能会造成MAC地址泄露
- 空间开销大(这点大部分情况可以忽略)
如何优化?
可以在UUID前拼上时间段,使UUID趋势递增。
1.2 基于数据库
1.2.1 自增主键
数据库的自增主键可以用来做分布式ID,以Mysql为例
1 | |
获取ID的方式:往SEQID表插入表插入一行记录,获取最新ID。
1 | |
优点
- 实现简单
- 严格单调递增
缺点
- 单库存在性能瓶颈(1e6/s)
- 存在单点故障
- 需要引入DB依赖
1.2.2 自增主键-集群模式
单库作为ID生成器,存在性能瓶颈和单点故障风险。一个简单的优化方式是,引入集群模式,多DB实例发号。
1 | |
优点
- 性能可线性扩展
- 具备容灾能力
缺点
- 实现复杂,难维护
- 难扩容
1.2.3 Segment(号段)模式
以上两种方式,都是使用DB自增主键作为分布式ID。
获取ID的流程为
- 插入一行记录
- 获取并返回记录主键ID
插入记录需要IO开销,当数据规模增大(1e7/s),会成为性能瓶颈。
一种常见解决方法是,引入号段模式,每次请求发放一组ID,减少IO次数。
1 | |

优点
- 解决DB IO性能瓶颈
缺点
- 需要额外引入IDGen服务
- 实现稍复杂,难维护
- 需要DB依赖
1.3 Snowflake
Snowflake是Twitter公司采用的一种算法,使用int64正数部分作为ID。Snowflake及其变种,如MongoDB ObjID,在业内应用较为广泛。
1 | |
组成部分(64bit)
- 第一位 占用1bit,其值始终是0,没有实际作用。
- 时间戳 占用41bit,精确到毫秒,总共可以容纳约69年的时间。
- 工作机器id 占用10bit,其中高位5bit是数据中心ID,低位5bit是工作节点ID,做多可以容纳1024个节点。
- 序列号 占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID。
Snowflake算法在同一节点毫秒内最多生成的ID数量 = 1024 X 4096 = 4194304
优点
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
1.4 方案对比
| 方案 | 长度 | 趋势递增 | 单调递增 | 依赖三方组件 | 关键缺点 |
|---|---|---|---|---|---|
| UUID | 128bits | 否 | 否 | 否 | version-1存在暴露MAC地址风险 |
| DB自增ID | 64bits | 是 | 是 | 是 | 依赖DB,重 |
| DB集群模式 | 64bits | 是 | 否 | 是 | 依赖DB,重 |
| DB号段模式 | 64bits | 是 | 否 | 是 | 依赖DB,重 |
| Snowflake | 64bits | 是 | 否 | 否 | 存在时间回拨 |
二 业界实践
这一部分分享业内成熟的分布式ID生成器实践。
2.1 uid-generator (百度)
uid-generator基于Snowflake实现,调整位数分配为1-28-22-13,使用秒时间戳。
相比Twitter的Snowflake,支持更大规模多实例部署(2^22=4194304)。百度的思路是把uid-generator作为lib整合到服务中,无需独立部署ID生成器服务。
1 | |
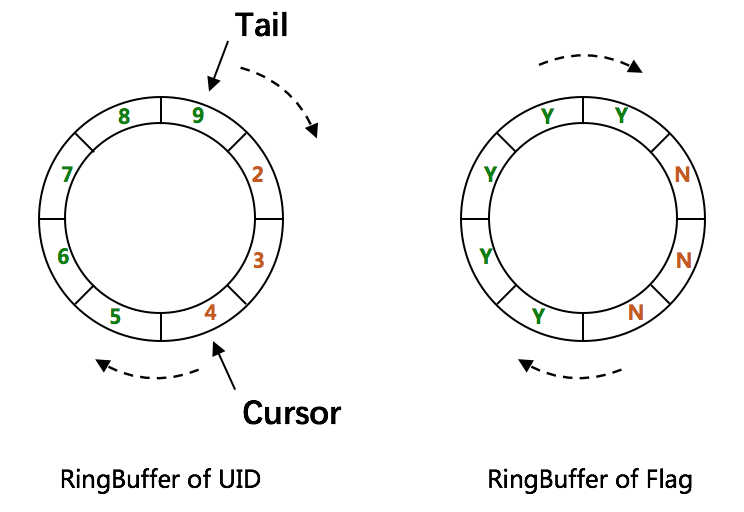
使用秒时间戳,同一秒同一节点生成的ID连续分布,容易被扫描攻击。百度的解决思路是引入双环形缓存,按一定策略异步生成缓存ID,减少ID连续性。
总结
百度uid-generator的出发点是去ID生成器服务。为此增加ID中的WorkerID位数,减少Timestamp位数,采用秒时间戳,引入缓存机制减少ID连续性,实现较复杂。
优点是无需独立部署独立ID生成器服务,建议只在不复杂的单体服务中使用。
2.2 Leaf(美团点评)
Leaf是美团点评的分布式ID生成系统,提供segment和snowflake两种模式,分别对DB Segment模式和Snowflake做了优化。
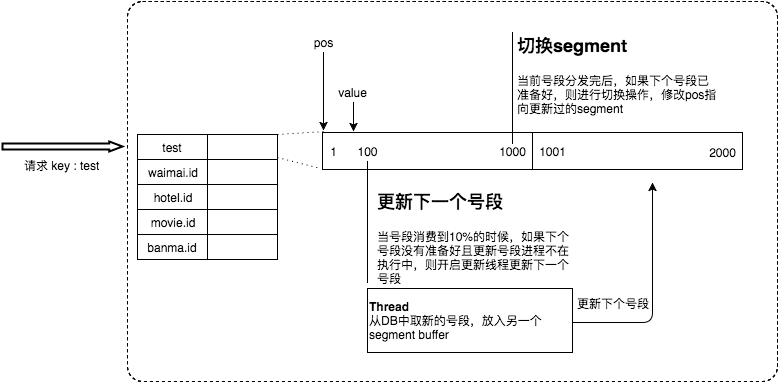
Leaf-Segment模式
Leaf-segment模式依赖DB,采用Segment模式。在传统Segment模式实现上加上双buffer优化,解决发号服务某一号段用完,重新申请号段可能引起的请求耗时抖动。
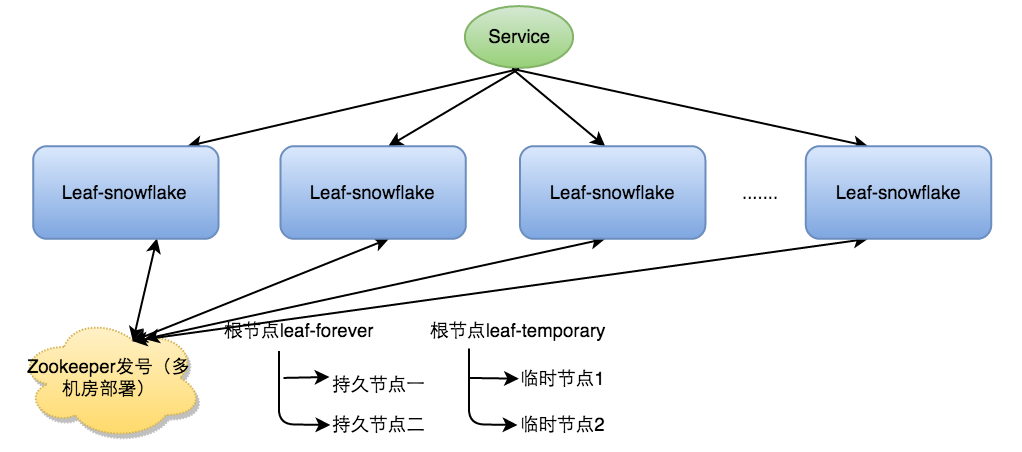
Leaf-snowflake模式
snowflake方案在集群模式下如何保证多实例workerID不冲突?
Leaf-snowflake模式在snowflake算法基础上引入zk依赖,用zk给每个idgen服务发号,保证workerID不冲突。
总结
Leaf是美团优化实现的分布式ID生成器成熟方案,实用性较强。
2.3 微信seqsvr
IM场景要求用户消息序号严格单调递增,snowflake无法保证。微信自研并演进出一套序号生成器架构,具有很高参考价值。
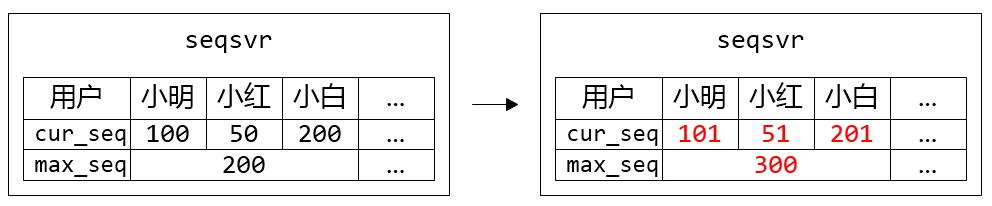
微信使用int64作为ID,每个用户有独立序号空间,每个序号空间序号严格递增。

类似于DB自增主键方式,为了减少获取ID的IO频率,引入号段max_seq。当seqsvr故障重启,加载max_seq恢复发号。
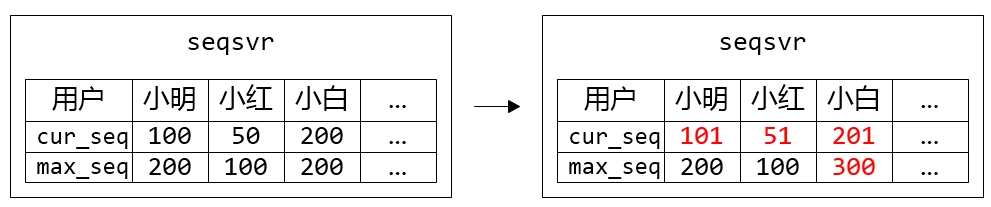
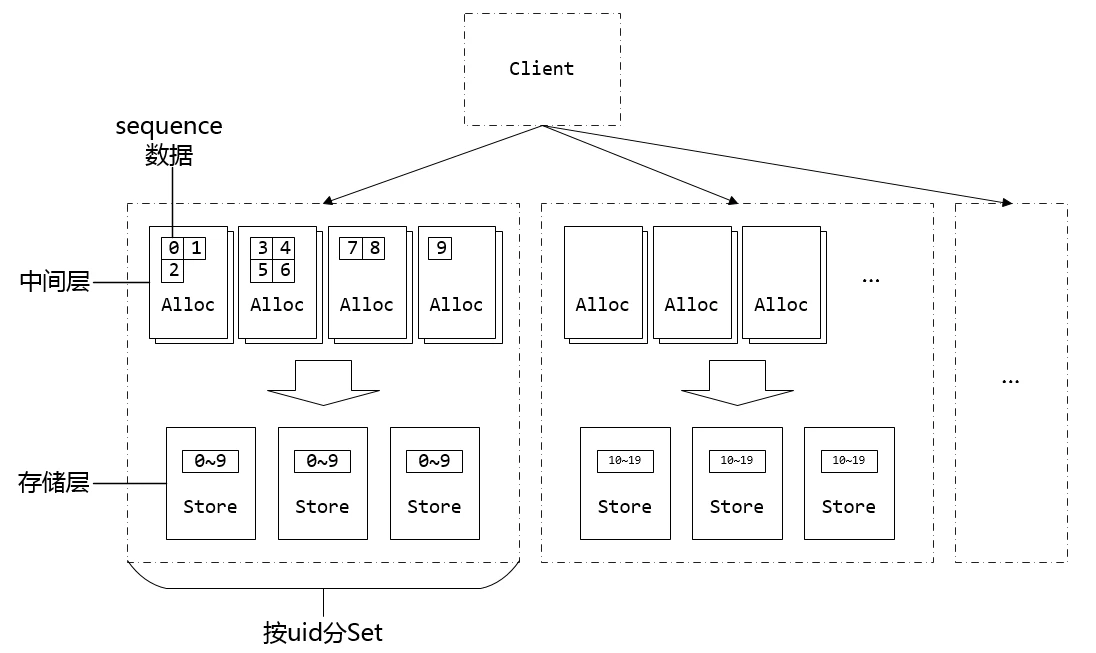
每个用户独立8bytes max_seq,在微信亿级用户规模下,存储开销大(以2^32估计,数据大小一共为32GB),故障恢复耗时高。微信的优化方式是,引入用户Section的概念,uid相邻的一段用户属于一个号段,而同个号段内的用户共享一个 max_seq,这样大幅减少了 max_seq 数据的大小,同时也降低了 IO 次数。对用户分段,使多个用户公用同一个max_seq。(实践上,一个Section包含10万个uid)
工程实现上,将系统分离为中间层和存储层,既方便中间层容灾,也方便存储层扩容。
总结
微信ID生成器的架构设计,体现了在复杂工程上把握关键点,保持简单设计的智慧,在工程上有很高参考价值。